GitLab permet de lancer des tests automatiques à partir du moment où un fichier .gitlab-ci.yml existe à la racine de votre dépot git (et que la configuration est faite côté serveur GitLab).
Par exemple si vous voulez lancer automatiquement le test avec phpstan vous pouvez créer un fichier .gitlab-ci.yml comme ceci:
stages:
- phpstan
cache:
paths:
- .tmp/
- vendor/
phpstan:
stage: phpstan
script:
- /usr/local/bin/phpstan.sh
Il aura pour effet de lancer le script /usr/local/bin/phpstan.sh sur le runner qui exécutera le test.
Proposition du contenu du fichier /usr/local/bin/phpstan.sh
#!/bin/bash
if [ ! -f .phpstan.gitlab.neon ]; then
echo "there is no phpstan dedicated file for gitlab in that project"
exit 0
fi
if [ -f composer.json ]; then
composer i
fi
/home/gitlab-runner/composer/vendor/phpstan/phpstan/phpstan analyse --error-format gitlab --no-progress -c .phpstan.gitlab.neon --memory-limit 6G
Pourquoi lancer un script /usr/local/bin/phpstan.sh plutôt que la commande directe ? Pour une question d'optimisation vis à vis de notre infrastructure et surtout ça permet de travailler en équipe: le développeur souhaite que phpstan soit lancé mais pour autant doit il spécifier la commande à lancer ? ou peut-il s'appuyer sur les compétences croisées de son administrateur système qui connaît bien le serveur qu'il a installé et qu'il met à disposition du développeur pour lancer ses tests ?
Cette approche ne peut fonctionner que pour une seule raison : GitLab permet d'auto-héberger sa plate-forme. Et vous le savez chez CAP-REL ça fait partie des raisons pour lesquelles une solution technique est choisie ou pas ... vous en avez la un exemple.
Et comme nous hébergeons "notre" GitLab nous pouvons construire "notre" architecture selon "nos" contraintes. Et pour ce qui est de GitLab comme nous pouvons créer nos "runner" (les serveurs qui vont lancer les commandes orchestrées par le serveur GitLab) nous pouvons intervenir sur le processus.
Le recours à un script shell "local" est une astuce qui remonte à notre expérience du temps d'AbulÉdu: à cette époque nous utilisions jenkins pour builder automatiquement tous les logiciels du Terrier (entre autre) pour lesquels il fallait produire des paquets deb (pour debian & ubuntu) et des fichiers exe pour windows. Les développeurs n'ont pas forcément en main toutes les astuces des "mainteneurs de paquets", le développeur se contente d'ajouter le nom du script à lancer pour le build de son logiciel et c'est tout. C'est une autre équipe (dont il peut éventuellement faire partie) qui implémente les outils de build.
Le fait de lancer un script permet dans notre cas à l'administrateur local du runner d'adapter la commande en fonction des spécificités de la machine, de son os, des capacités, des ressources allouées etc. et de ne rien faire si le fichier .phpstan.gitlab.neon n'est pas présent
Pourquoi utiliser le fichier .phpstan.gitlab.neon plutôt que le fichier par défaut ? tout simplement car le développeur pourrait avoir un fichier spécifique pour sa machine de dev et que les règles applicables sur son poste ne le sont pas sur le serveur !
Ainsi dans le cas de phpstan le script pourrait lancer phpstan avec une option --memory-limit 6G ou --memory-limit 18G ...
Des "runner"
Pour que gitlab puisse lancer les tests d'intégration continue il faut qu'il puisse déléguer ces tâches très gourmandes à des serveurs qu'on appelle des "runner".
L'installation d'un runner est documenté, il suffit de suivre pas à pas la doc. Comme toujours plusieurs approches existent: il y a les fan du "serverless" qui délèguent tout au cloud, j'envoie, ça scale, ça revient. Plus je mets de $$$ dans le serverless cloud et plus j'espère avoir de ram, cpu, et un retour rapide ... Chez nous c'est l'inverse nous avons une approche plus près du hardware du fait que nous gérons notre parc nous-même. Si c'est lent et qu'il faut plus de ressources on cherche des solutions, louer de nouveaux serveur baremetal ? optimiser un processus ? garder des données en cache ? dédier des serveurs à certains outils de tests ou de compilation ? accepter moins de demande de tests ? mettre les serveurs de build en pause la journée (ils sont utilisés pour autre chose) et les activer le soir en dehors des heures de boulot ? ou au contraire il faut qu'ils soient disponibles pendant les heures où les développeurs bossent ? tout ceci est lié à notre organisation ...
Dans notre cas, les runners sont configurés comme ceci: shell executor ce qui nous permet d'avoir la main sur tout le process qui tourne dans le runner. Nos différents runner sont des conteneurs virtualisés sur nos serveurs.
Par exemple l'administrateur système peut décider que l'espace de stockage du cache de phpstan est un espace "ramfs" car très souvent sollicité par exemple où bien un ssd alors que le reste des données est sur un disque "hdd" ... L'admin sys a des outils à disposition pour faire des choix qui ne sont pas forcément accessibles au développeur (iotop, htop, time, etc.) ...
Si nous avions une infra docker (qui serait effectivement notre choix dans certains cas) nous aurions fait le choix d'utiliser la configuration docker de runner gitlab. Notez que l'intégration de docker dans GitLab est super propre et optimale.
L'affectation d'un runner à tel ou tel projet est géré par GitLab ce qui fait qu'il est aisé de cloisonner les projets, les serveurs, les ressources allouées etc.
Le résultat
Une fois tout ceci mis en place, que se passe-t-il ?
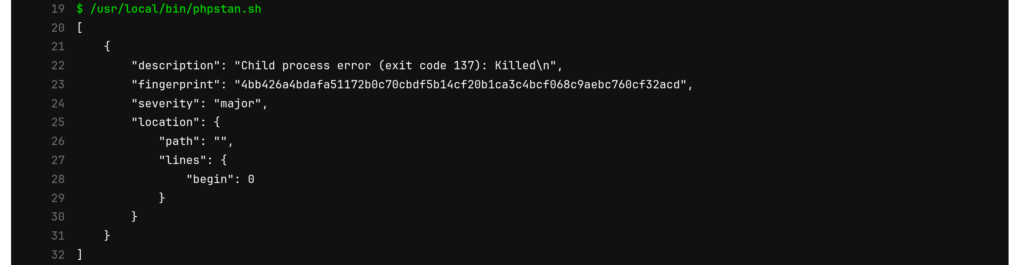
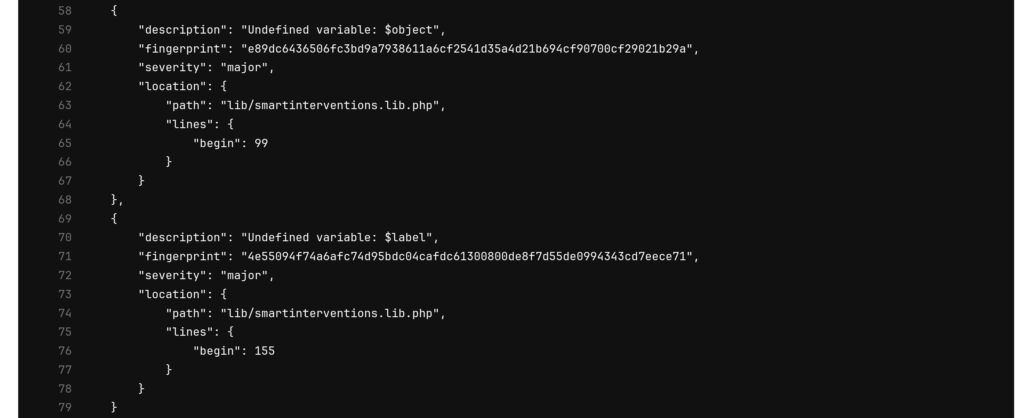
GitLab peut vous envoyer le compte rendu par email et vous affiche tout ceci sur son interface web. En particulier lorsqu'il y a une erreur comme vous pouvez le voir ci-dessous:

C'est tout pour cet article concernant GitLab et l'intégration continue avec un exemple sur phpstan.
Note: Je suis encore à la recherche d'une solution pour "remonter" l'erreur dans mon IDE, je suis persuadé que c'est possible mais je ne sais pas encore comment faire alors je regarde d'un côté le rapport "web" et je code la solution dans mon IDE.