Avant de vous parler des stubs en php je vais faire un petit détour par un autre langage : C/C++ (en fait ce qui est important c'est d'avoir un langage compilé comme support d'exemple).
En C/C++ le code source est découpé en deux fichiers: un fichier de code (le .cpp) et un fichier dans lequel se trouvent les entêtes des fonctions (le .h) et les descriptions de base des classes.
Un exemple avec un logiciel issu du projet AbulÉdu pour lequel je me suis totalement investi pendant des années:
Voici le fichier .h de l'objet permettant de s'authentifier sur un serveur AbulÉdu via un mécanisme SSO.
#ifndef ABULEDUIDENTITESUIV1_H
#define ABULEDUIDENTITESUIV1_H
#include <QWidget>
#include <QPixmap>
#include <QInputDialog>
#include "abuleduapplicationv1.h"
#include "abuleduidentitesv1.h"
#include "ui_abuleduidentitesuiv1.h"
#include "abuleduloggerv1.h"
namespace Ui {
class AbulEduIdentitesUIV1;
}
class AbulEduIdentitesUIV1 : public QWidget
{
Q_OBJECT
public:
explicit AbulEduIdentitesUIV1(QWidget *parent = 0);
~AbulEduIdentitesUIV1();
/**
* Avant de faire appel à cette fonction il faut s'authentifier sur le SSO à l'aide de ce genre de choses:
*
*/
void abeLoad();
/** Refresh */
void abeRefresh();
public slots:
/** Retourne un pointeur vers l'identité de l'utilisateur */
AbulEduIdentitesV1 *abeGetIdentite(const QString &login);
private slots:
void slotChoixAvatar(const QString &avatar);
void slotIdentitieLoaded();
void slotMessageAvailable(const QString &message);
void on_btnUpdate_clicked();
void on_btnUnifier_clicked();
void on_cbIdentite_currentIndexChanged(const int index);
void on_btnMesLogs_clicked();
void on_btnPhoto_clicked();
void on_lePassword1_textChanged(const QString &arg1);
void on_lePassword2_textEdited(const QString &arg1);
void on_btnUpdateAvatar_clicked();
void on_btnAnnuler_clicked();
void slotSelectAvatar();
protected:
void hideEvent(QHideEvent *);
private:
Ui::AbulEduIdentitesUIV1 *ui;
//La liste de toutes les identitées
QList<QPointer<AbulEduIdentitesV1> > m_identites;
//Et mon identitée principale
AbulEduIdentitesV1 *m_abuleduIdentite;
QPushButton *m_selectedAvatar;
bool m_localDebug;
signals:
void signalAbeIdentityUpdated();
};
#endif // ABULEDUIDENTITESUIV1_HEn bref la seule chose qui pourrait nous intéresser de ce fichier .h c'est de savoir qu'il est possible de faire appel aux fonctions publiques abeLoad, abeRefresh et que abeGetIdentite retourne un pointeur de type AbulEduIdentitesV1 (c'est un objet qui permet de stocker tout ce qui concerne les informations utilisateur).
Il n'est pas nécessaire d'avoir le fichier .cpp beaucoup plus long (car contenant l'implémentation totale de toutes les fonctions) pour savoir comment s'interfacer avec cet objet.
Une raison importante est que vous pouvez avoir une bibliothèque compilée avec laquelle vous devez échanger des données, le code de la bibliothèque n'est pas forcément disponible (car compilée), le fichier .h est suffisant pour pouvoir l'utiliser et interagir avec elle. C'est pratique même pour des projets libres (il n'est pas nécessaire de parcourir les Go de données de Qt pour pouvoir compiler des logiciels qui utilisent la bibliothèque Qt).
Retour à PHP
Le PHP n'a pas ce découpage et tout se trouve dans le fichier .php ... ce qui n'est pas identifié comme un problème tant que vous avez un petit projet monobloc. Mais dès que vous commencez à travailler sur des projets modulaires pour lesquels vous n'avez pas forcément accès à tout le code où que celui-ci devient vraiment important (c'est le cas de dolibarr et de ses 14.000 fichiers dont plus de 4300 php) vous pouvez toucher du doigt le problème.
La première fois que j'ai entendu parler de stubs c'est chez phpstom de la à leur attribuer la paternité de ce "truc" il n'y a qu'un pas que j'ose faire, l'idée est excellente et s'appuie sur un autre outil bien connu des développeurs PHP : phpdoc qui apporte une syntaxe particulière que nous suivons pour documenter le code PHP.
Le Stubs est donc le résultat de l'extraction de tout un fichier php dont on aurait viré la charge utile en ne gardant que la doc, les empreintes des fonctions et des objets. En bref le stubs est à php ce que le .h est à c++. Sauf que le stub est un seul gros fichier là où nous avions des centaines de fichiers .h pour des gros projets c++.
Concrètement ça donne quoi ?
Pour faire un résumé:
- l'ensemble des fichiers php de dolibarr pèse 66Mo répartis en plus de 4300 fichiers dans plus de 1500 dossiers, si votre environnement de développement (IDE) doit "manger" le code du coeur de dolibarr pour souligner d'une vaguelette rouge une erreur d'appel de fonction ça représente une charge initiale importante (ouverture, parcours de l'arborescence, indexation)
- le fichier stub correspondant à la même arborescence de dolibarr sous la forme d'un seul fichier pèse 12Mo ... le temps de chargement et l'espace mémoire nécessaire est drastiquement optimisé
- je n'ai pas besoin du code de dolibarr pour implémenter un module externe et faire en sorte que mon IDE m'accompagne sur l'auto-complétion des fonctions et/ou les alertes liées au code du coeur de dolibarr
- je peux lancer des outils d'analyse & de tests de manière optimale (article à suivre sur phpstan par exemple)
- j'économise du temps cpu, de la ram
- l'effet d'échelle est important si vous mettez en place des outils d'intégration continue pour vos modules dolibarr: 1.4 Go de données à chaque test si vous téléchargez une branche de dolibarr contre 15 Mo ... multiplié par le nombre de versions de tests ... (article à suivre sur l'intégration continue des modules)
Et donc pour dolibarr:
- j'ai ajouté ceci sur le wiki pour les développeurs : https://wiki.dolibarr.org/index.php?title=Outils_de_d%C3%A9veloppement#Stubs_ou_extraits_de_codes
Le résultat est tout simplement d'avoir ce genre de choses dans votre IDE sans pour autant avoir le code source de dolibarr sur votre machine:
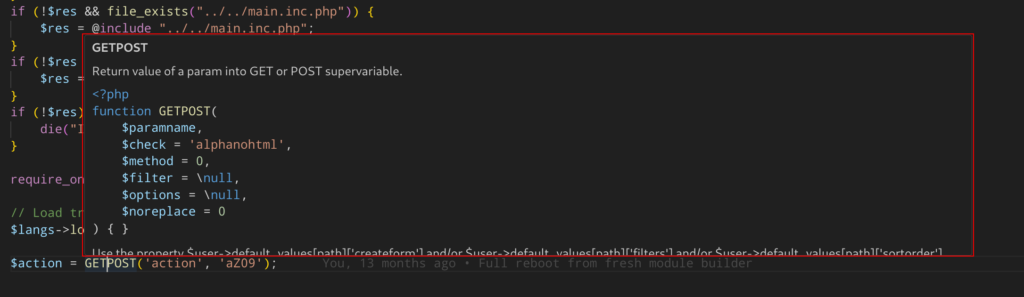
CAP-REL vous propose des fichiers stubs préparés ainsi que la recette si vous voulez le faire vous même: https://packagist.org/packages/caprel/dolibarr-stubs